
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- jpa
- 생활코딩
- 컴퓨터 구조
- LCS
- CI/CD
- 그리디
- 삼성SW역량테스트
- 수학
- Air Table
- 삼성 SW 역량테스트
- Cloud Pub/Sub
- 다익스트라
- REACT
- 백준 1753번
- 종만북
- 시뮬레이션
- 다이나믹 프로그래밍
- 고속 푸리에 변환
- 우선순위 큐
- 데이터 분석
- BFS
- Cloud Run
- 펜윅 트리
- dp
- ICPC
- JavaScript
- 접미사 배열
- 이분탐색
- r
- Bit
- Today
- Total
코딩스토리
Kafka - 서비스에 적용하기 위한 궁금증들 본문
# 해당 포스팅은 "카프카-데이터 플랫폼 최강자 (저자 고승범)" 도서를 읽으며 공부한 내용입니다.
서론
카프카를 공부하기 전에 이미 여러 블로그들을 보면서 프로듀싱 서버와 컨슈머 서버를 구성했다.
하지만 정말 "pub sub 구조"라는 단편적인(단편을 넘어서 거의 백지상태😂) 지식만을 가진 상태로 구현하다 보니 많은 궁금증들이 생겼다.
그래서 이 글에서는 내가 느꼈던 궁금증들을 토대로 공부한 내용을 정리해보려고 한다.
카프카의 기본 개념에 대해서는 이미 많은 블로그들이 잘 정리해 놓았기 때문에 이 부분은 패스!!
나도 크게 세 가지 개념 정도만 알고 이 책을 읽었기 때문에 아래 내용들에 대해서 알고 있다면 글을 읽는데 무리가 없을 것이다.
(아래 질문에 대해서 예시 답변정도로만 답할 수 있다면 충분!!)
- Q) 카프카란?
A) Pub Sub 구조의 분산 이벤트 스트리밍 플랫폼
- Q) 프로듀서와 컨슈머, 브로커의 역할과 그들 사이의 데이터 흐름은?
A) 프로듀서 = 메시지(이벤트) 생성, 브로커 = 토픽 관리, 컨슈머 = 토픽 구독 및 메시지 처리, 흐름 = 프로듀서 -> 토픽 -> 컨슈머
- Q) 카프카 아키텍처의 구성은 어떻게 되는가?
A) 토픽 = 여러 개의 파티션, 브로커 = 카프카 서버, 프로듀서, 컨슈머 등등
1. 카프카에서 메시지 순서 보장이 될까?
내가 구현하던 컨슈머 서버에서 시간 값을 갱신하는 로직을 추가하고 싶었다.
예를 들어 프로듀싱 서버에서 어떠한 api가 호출됐을 때, 이벤트가 발생한 시간들을 메시지에 담아서 보내면
컨슈머가 그 값들을 지속적으로 소비해서, 해당 값을 db에 업데이트하며 api가 호출된 "가장 최근 시간"을 관리하고 싶었다.
내가 예상한 대로 동작하려면, 카프카가 메시지의 순서 보장이 돼야 한다.
예를 들어 api가 3번 호출됐는데, 시간이 각각 1분 차이라고 하자. (ex. 12:01분 -> 12:02분 -> 12:03분)
이때 메시지가 순서대로 오지 않는다면 가장 최근 시간을 잘못 저장하는 경우가 발생한다.
위의 예에서
12:01분 메시지 도착 -> 12:03분 메시지 도착 -> 12:02분 메시지 도착
이런 순서대로 컨슈밍 하게 된다면, 내가 알고 있는 값은 12:02분에 마지막으로 api가 호출됐구나!라고 생각할 수 있다.
(물론 이미 저장돼 있는 값과 비교해서 가장 최근 값을 집어넣으면 되지만 가정이니까..😆)
그럼 이제 궁금해진다. 과연 카프카는 메시지 순서 보장이 될까?
카프카는 하나의 토픽이 여러 개의 파티션으로 구성된다.
토픽이 파티션으로 나뉜 이유는 아래 비교 그림을 통해서 쉽게 이해할 수 있다.

파티션이 나뉘지 않으면 메시지를 보내는데 4초가 걸리지만 파티션이 나뉘면 1초 만에 전부 보낼 수 있다.
고성능의 아키텍처를 위해선 파티션은 필수인 것이다.
그럼 파티션 내부에서는 어떻게 메시지가 보관될까?
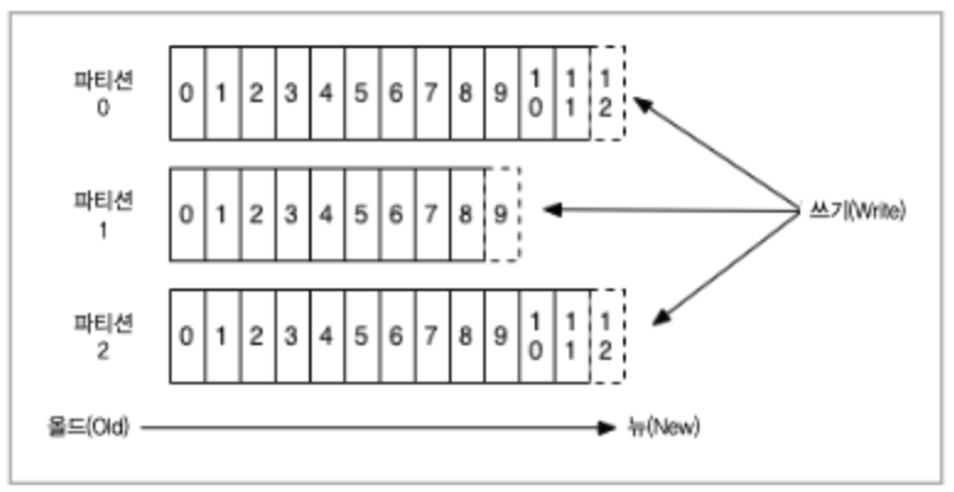
각각의 파티션은 메시지의 오프셋 값을 가진다.
FIFO 구조의 Queue처럼 처음 들어간 메시지부터 오프셋 값이 증가하도록 되어있다.
결론적으론 사실 이 그림만으로도 질문에 대한 답을 얻을 수 있다.
파티션 내부에서는 메시지의 순서가 보장된다.
하지만 파티션이 여러 개일 경우엔 파티션끼리의 순서는 보장되지 않는다.
파티션의 개수는 토픽 생성 시 정해줄 수 있는데, 반드시 메시지 순서가 보장되어야 한다면 하나의 파티션으로 구성하면 된다.
하지만 파티션을 한 개로 구성하게 된다면 하나의 컨슈머만 처리가 가능하기 때문에 이는 충분히 고려 후 설계해야 한다.
카프카에서는 파티션을 늘리는 건 가능하지만 줄이는 건 불가능하기 때문에
메시지 순서가 보장되어야 할 이슈가 조금이라도 있다면 처음엔 파티션을 1로 잡아놓고 나중에 늘려나가는 것이 좋다.
2. 카프카는 어떻게 HA를 만족하지?
실서비스 운영에 있어서 HA(고가용성)은 점점 필수가 되어가고 있다.
특히나 트래픽이 많거나 장애에 민감한 서비스의 경우 HA는 아키텍처 설계 때 필수로 고려해야 할 부분이다.
최근 들어 더욱 서비스 장애에 민감해진 상황에서 HA를 고려하지 않을 수 없었고, 카프카의 HA가 궁금했다.
카프카는 어떻게 HA를 구성할까??
결론부터 말하면 카프카는 리플리케이션, ISR 등을 통해 HA를 구성한다.
먼저 리플리케이션은 말 그대로 "복제"란 의미이다.
쿠버네티스를 경험해 본 사람이라면 k8s 역시 replica를 통해 HA를 구성한다. (물론 replica로만 HA를 구성할 수 있는 건 아님!!)
이와 비슷한 개념이다.
즉 브로커(카프카 서버)가 여러 대 있을 때, 토픽의 리플리케이션 값을 지정해 주면 복제본들이 서로 다른 브로커에 구성된다.

위의 그림은 브로커가 3대 있을 때, 토픽의 리플리케이션을 2로 잡은 예시이다.
이때 토픽은 하나의 리더를 가지고 나머지 리플리케이션은 전부 팔로워의 역할을 한다.
(실제로는 토픽이 아닌 파티션이다. 하지만 책에서는 이해를 돕기 위해 토픽이라고 표현했다고 한다.)
프로듀서는 현재 리더만 바라보며 데이터를 프로듀싱하면 된다. (프로듀서는 리더가 바뀌는 것에 관심을 가질 필요가 없다.)
팔로워들은 리더를 바라보며 계속해서 데이터를 동기화한다.
리더가 있는 브로커가 장애가 발생하면, 자연스럽게 살아있는 팔로워 중 한대가 리더의 역할을 맡게 된다.
이쯤에서 궁금한 게 있어야 한다.
근데.. 그러면 데이터 정합성에 문제가 생기지 않을까요??
예를 들어 프로듀서가 메시지를 리더 브로커에 보냈다.
리더는 해당 메시지를 적재한다.
그다음 팔로워들은 리더의 데이터 변화를 동기화하려고 한다.
이때!!! 동기화 전에 리더 브로커에 장애가 발생했다. (상상만 해도 싫지만 세상일은 정말 모르니까..😭 누가 데이터 센터에 불날 줄 알았겠냐고~)
그럼 팔로워가 데이터가 동기화되기 전에 리더가 되게 된다.
리더가 되는 순간 다른 팔로워들은 새롭게 선출된 리더를 바라보게 되고, 데이터 동기화를 진행한다.
결국 가장 최초의 리더가 적재한 메시지는 처리할 수 없게 된다.
이러한 데이터 정합성 문제를 해결해 주는 방법이 바로 ISR이다.
ISR은 "데이터의 정합성이 완벽한 후보 그룹"이라고 생각하면 편하다.
팔로워가 5명일 때, 5명 모두 데이터 정합성을 맞추는 건 어렵다.
하지만 1명에 대해서만 정합성을 맞추는 건 더 빠르고 완벽하게 수행할 수 있다는 것이다.
그래서 이렇게 리더와 데이터 정합성이 보장되는 팔로워들을 합친 그룹을 ISR이라고 한다.
이제 리더에게 문제가 생겼을 시, 모든 팔로워가 아닌 ISR에 있는 팔로워들 중 한 명을 리더로 선출하면 데이터 정합성을 보장받을 수 있게 된다.

위 그림처럼 ISR 안에 팔로워들이 존재하고, 새로운 리더 선출 시 반드시!! ISR에서 선출한다는 것이다.
이렇게 다양한 방법으로 카프카는 HA를 구성하고 있다.
3. 프로듀서가 브로커로 메시지를 보낼 때 문제가 생기면 어떻게 해?
카프카 아키텍처를 도입하면서 컨슈머의 역할이 더 중요하다고 생각하기 쉽다.
아마 대부분 처음부터 카프카를 구성했던 게 아니라면, 기존에 운영되고 있던 서버가 프로듀싱 서버가 될 것이다.
프로듀싱 서버는 이벤트가 발생하는 시점에 적절한 이벤트를 브로커로 send()만 하면 된다고 생각하기 쉽다.
(내가 그렇게 생각했단 건 안 비밀..🤣)
나도 처음엔 컨슈머 서버 쪽에 집중하다 순간 불안한 생각이 뇌를 스쳤다.
잠시만.. 프로듀싱 서버 쪽에서도 에러 처리를 해야 하지 않나??
예를 들어 프로듀싱 서버에서 이벤트를 잘 만들었고 이를 브로커로 전송했다.
이때 만약 네트워크 오류로 인해 해당 이벤트가 브로커까지 전달이 잘 안 된다면??
(1년이라는 내 짧은 경험을 빗대어보면 충분히, 그리고 자주 발생할 수 있는 상황이라고 생각한다.)
프로듀서는 카프카로 메시지를 보낼 때 크게 두 가지 방식을 선택할 수 있다.
첫 번째는 동기 방식이다.
프로듀서가 메시지를 보낸 뒤, 브로커에서 응답을 줄 때까지 기다린다는 것이다.
응답에 따라 에러 처리를 할 수 있기 때문에 위의 가정에 대응할 수 있다.
두 번째는 비동기 방식이다.
프로듀서가 메시지를 보내고 응답을 기다리지 않는다.
나중에 응답을 받고 그에 따른 처리를 할 수 있지만 메시지의 손실 가능성이 있다.
동기 방식은 안전하지만 서비스 운영에 있어서 문제가 생길 수 있다.
유저가 API를 호출했을 때, 해당 API의 로직 안에서 send()를 한다고 생각해 보자. (대부분 이렇게 구현될 것이다.)
하지만 어떻게 보면 이벤트를 스트리밍 하는 것은 사용자에게 있어서 불필요한 로직이다.
만약 동기 방식으로 구현하게 된다면, 유저는 카프카의 응답도 기다려야 하고
카프카 쪽에서 문제가 생긴다면 서비스 로직은 정상적으로 수행했음에도 응답을 못 받는 경우도 생기게 된다.
그렇다고 비동기 방식으로 진행한다면 "메시지의 손실 가능성"이라는 문제를 안게 된다.
비동기 방식으로 메시지의 손실을 막을 수 있는 방법은 없는 걸까??
카프카는 비동기 방식에서 메시지의 손실을 낮추기 위해 "acks"란 옵션을 사용한다.
acks란 쉽게 풀어써보면 데이터가 제대로 적재되었을 경우 보내주는 신호이다.
acks 옵션은 크게 0, 1, -1(=all) 이렇게 3가지 값을 가지게 된다. 이때 acks의 값은 데이터가 제대로 적재된 파티션의 개수가 된다.
살짝 이해가 안 될 수 있는데 아래 값들을 비교해면서 이해해 보자.
- acks = 0
- 데이터가 제대로 적재되었는지 확인하지 않겠다는 것이다.
- 당연히 메시지 전송 속도는 여러 값 중 가장 빠르게 될 것이다.
- 일반적인 상황에서는 크게 문제가 없지만 장애 상황의 경우 메시지 손실 가능성이 높아진다.
- acks = 1
- 데이터가 제대로 적재된 파티션이 하나만 있으면 된다는 것이다.
- 프로듀서는 늘 리더를 바라보고 있기 때문에 결국 리더만 적재되면 OK 하겠다는 것이다.
- 적당한 성능에 메시지 손실 가능성이 적은 방법이며 일반적으로 가장 많이 사용되는 옵션이다.
- acks = -1 (all)
- 데이터가 모든 파티션에 제대로 적재되어야 한다는 것이다.
- 리더와 모든 팔로워들(리플리케이션)에 데이터가 제대로 적재되면 그때 OK 하겠다는 것이다.
- 손실 가능성이 없지만 응답속도가 느리다.
acks = 1이 일반적으로 가장 많이 사용되는 옵션이기 때문에 대부분의 개발자가 이 옵션을 택하지 않을까 싶다.
하지만 메시지 손실 가능성이 적은 방법이기 때문에 아래와 같은 상황에선 메시지의 손실이 일어날 수 있다.
프로듀서가 리더에게 메시지를 보냈고, 리더가 정상적으로 적재해서 ack 신호를 날렸다.
이때 ack를 보낸 직후 리더에서 장애 발생 시, 팔로워들은 아직 데이터를 리더와 동기화하지 못한 상태이다.
하지만 프로듀서는 ack를 받았기에 정상적으로 데이터를 적재했다고 판단할 수밖에 없다.
그렇게 되면 메시지의 손실이 일어나게 된다.
정말 특이한 상황이기 때문에 내가 개발자로 사는 동안 마주칠 일이 있을까 싶지만.. 그래도 기억해 놓자!
만약 이런 특이한 상황조차 가정하기 싫고 불안하다면 acks = all을 쓰는 게 맞을 것이다.
이때 조심해야 하는 건 all을 의도한 대로 쓰려면 리플리케이션의 개수를 2개로 설정해야 한다.
1개로 설정하면 acks = 1과 같이 동작하기 때문이다.
4. 컨슈머가 데이터를 중복으로 소비하진 않을까?
어떠한 api가 호출됐을 때 이벤트가 발생하고, 이를 컨슈밍 해서 api 호출 카운트를 1씩 증가시키는 컨슈머 서버를 구현하고 싶었다.
하지만 해당 api가 너무나도 많은 호출량으로 인해 컨슈머 서버가 한대로는 버티기 어려울 것 같았다.
나는 이를 셀에서 사용 중인 k8s를 사용해서 여러 대의 파드를 띄워서 해결하려고 했다.
즉 완전히 동일한 컨슈머 서버가 여러 대가 존재하는 것이다.
근데 만약 여러 대의 컨슈머가 같은 이벤트를 동일한 로직으로 수행해 버리면, 실제 이벤트는 1번 발생했는데 파드 개수만큼 증가되는 게 아닌가??
(사실 이 걱정은 구현하기 전부터 했었던 고민이었다🤔)
즉, 컨슈머가 데이터를 중복으로 소비하진 않을까??
이 부분도 결론부터 얘기하면 "컨슈머 그룹"을 통해서 메시지를 중복으로 소비하지 않도록 할 수 있다;
컨슈머 그룹이란, 하나의 토픽을 처리하는 여러 컨슈머들을 묶어놓은 그룹이다.
카프카는 토픽을 여러 파티션으로 나눌 수 있다. 그렇기 때문에 하나의 토픽을 여러 컨슈머가 소비할 수 있다.
(이 문단이 이해가 안 된다면, 토픽과 파티션을 확실히 구분지어서 생각해 보자!)
이때 하나의 파티션에는 컨슈머 그룹 내의 하나의 컨슈머만 연결할 수 있다.
왜냐하면 하나의 파티션에 여러 컨슈머가 붙게 되면 각 컨슈머의 메시지 처리 속도에 따라 메시지 소비 순서가 달라질 수 있기 때문이다.
예를 들어 A, B 컨슈머가 0번 파티션에 붙었을 때, A컨슈머가 1번 메시지를 처리하는데 딜레이가 생기고 있었다.
이때 B 컨슈머는 2번 메시지를 가져갔는데 딜레이 없이 빠르게 소비했다.
이렇게 되면 1번 메시지 처리 전에 2번 메시지가 처리되었기 때문에 같은 파티션 내에서도 소비 순서가 보장되지 않는다.
따라서 하나의 파티션에 하나의 컨슈머만 연결되면 아래와 같은 구조가 된다.
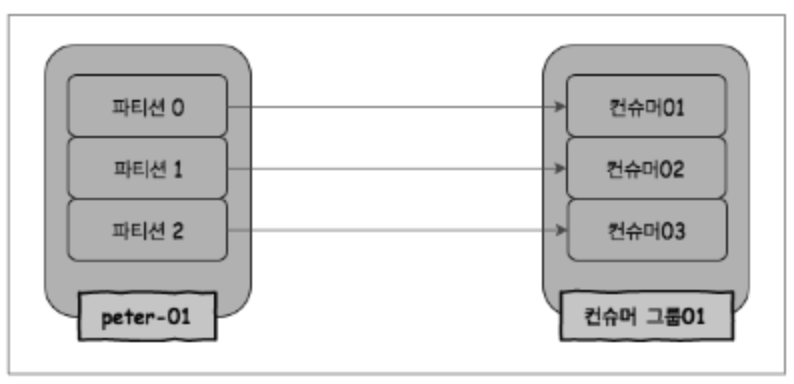
내 상황에 비유해 보면 컨슈머 01, 컨슈머 02, 컨슈머 03은 각각 k8s의 파드가 될 것이다.
각 파드마다 컨슈머 코드가 들어있을 것이고 이 코드에 컨슈머 그룹을 지정해 주면 된다.
아래는 Spring Kafka로 구현 시, groupId를 지정해 주는 예시 코드이다.
@KafkaListener(topics = [USER_API_TOPIC], groupId = USER_API)
fun consumeAddFavorite(event: String) {
log.info("[Consumer] Subscribing topics: {}", USER_API_TOPIC)
log.info("EVENT : {}", event)
}
이제 이 코드를 가진 동일한 서버가 여러 대 떠있어도, 이들은 전부 하나의 그룹이 된다.
그리고 파티션에 데이터가 적재되면 컨슈머 그룹 내의 하나의 컨슈머만 해당 데이터를 소비한다.
즉 그룹 내의 컨슈머는 데이터를 중복 소비하지 않게 되는 것이다.
이러한 이유로 컨슈머 그룹의 컨슈머 개수는 파티션 개수와 동일하게 유지하는 것이 좋다고 한다.
파티션 개수는 줄이기 어렵기 때문에 컨슈머 개수를 파티션 개수에 맞춰서 유지하는 게 더 좋다.
물론 동일하게 유지할 때도 문제는 발생한다.
만약 컨슈머 한대가 죽으면..? 이건 너무나도 자주 발생할 수 있는 상황 아닌가?
그렇게 되면 컨슈머 그룹 내부에서 리밸런싱을 통해 각 파티션을 컨슈머에게 다시 배정한다.

위에서 빨간색으로 강조했듯이 한 파티션에는 하나의 컨슈머만 연결된다.
하지만 하나의 컨슈머에는 여러 파티션이 배정되어도 문제가 되지 않는다.
대신 해당 컨슈머는 부하가 늘어나고 이후 어떠한 일이 벌어질지는 상상에 맡겨보겠다.🤪
그렇기 때문에 지속적인 모니터링을 통해 컨슈머 그룹의 부하를 확인해 주고 적절한 컨슈머 개수를 유지해야 한다.
그럼 여기서 또 한 번 문제가 생길 수 있다. (문제가 생길 수 있다만 몇 번 쓰는지 모르겠네요...😭)
위의 그림에서 컨슈머04가 열심히 데이터를 처리하고 있었다.
이때 컨슈머04가 죽고 컨슈머 그룹 내에서 컨슈머들이 리밸런싱 된다면 컨슈머04의 데이터 소비 상황을 카프카가 알지 못했다면
새로 배정받은 컨슈머03이 컨슈머04가 진행했던 작업을 중복처리 할 수 있다.
이 상황에서는 컨슈머04의 데이터 소비 상황(=오프셋)을 카프카가 몰랐다는 전제가 필요하다.
이 부분을 이해하기 위해선 먼저 컨슈머의 커밋에 대해서 알아야 한다.
카프카는 "커밋"을 통해 컨슈머 서버의 데이터 소비 지점(=오프셋)을 확인한다.
즉 커밋이란 컨슈머가 자신이 파티션의 데이터 중 어디까지를 가져갔는지(오프셋)를 카프카 쪽에 업데이트하는 작업을 의미한다.
만약 컨슈머가 0번 파티션의 데이터를 3번까지 소비했으면, 오프셋 값을 3으로 설정해서 커밋한다.
카프카는 이 커밋을 통해 컨슈머가 3번까지 데이터를 소비했음을 확인할 수 있다.
다시 위의 상황으로 돌아가서 자세히 설명해 보자면 컨슈머04가 커밋을 하기 전 리밸런싱 됐다는 것이다.
그렇다면 카프카는 컨슈머04가 어디까지 데이터를 소비했는지 모르기 때문에
리밸런싱을 통해 새롭게 파티션에 연결된 컨슈머03이 데이터를 중복해서 소비할 수 있다는 것이다.
다행히도 커밋의 시점을 조절하여 이러한 상황을 막을 수 있다.
커밋은 크게 두 종류로 나뉜다.
- 자동 커밋 : 매 주기(기본값 5초)마다 커밋함
- 데이터 중복 처리 발생 : 위에서 언급한 상황
- 데이터 손실 가능성 : 자동 커밋은 컨슈머가 데이터를 카프카로부터 제대로 받아왔는가? 만 확인함.
- 수동 커밋 : 메시지를 사용자가 소비를 한 후, 의도한 시점에 커밋
- 데이터 중복이 적어짐 : 롤백 → 트랜잭션을 예로 생각하면 됨
- 데이터 손실 방지
자동 커밋은 컨슈머가 데이터를 제대로 받아왔는가만 확인한다.
만약 서버 로직으로 이벤트 값을 db에 저장하다가 에러가 발생했다고 가정해 보자.
이미 카프카는 해당 컨슈머가 제대로 데이터를 받아갔다고 값을 받기 때문에 오프셋을 증가시켰을 것이다.
이는 처리하지 않은 오프셋이 발생하기 때문에 데이터 손실을 발생시킨다.
수동 커밋은 내가 원하는 시점에 커밋하기 때문에 데이터의 손실을 방지할 수 있다.
하지만 만약 DB에 저장을 하고 다른 에러가 난다면 수동 커밋은 데이터를 처리하지 못했다고 답할 것이다.
그럼 카프카에서 동일한 데이터를 가지고 오게 되고 중복 처리가 된다.
(서비스 로직에서 롤백을 생각하면 이해가 쉽겠죠?!)
최종적으로 정리하자면
중복을 완전히 방지할 순 없기 때문에 컨슈머 그룹과 커밋을 잘 이해해서 의도한 대로 동작할 수 있게 구현해야 한다.
(이 부분이 가장 궁금하기도 했고, 구현에 큰 영향을 끼치는 부분이라 더 자세히 적었는데 결과적으론 중복을 완전히 제거하는 건 불가능한 게 너무 아쉽다.. 실제로 카프카에서도 "메시지 처리를 적어도 한 번 보장한다"라고 하네요🥹)
5. 하나의 데이터를 여러 로직으로 분산처리가 가능할까?
유저가 api를 호출했을 때, 이벤트를 발생시켰다.
이때 나는 api 호출 이벤트 하나로 카운트 값도 증가시키고 싶고, 최근 호출 시간도 갱신하고 싶다.
또 나중에 언제든지 다른 셀원분들이 해당 이벤트를 사용해 어떠한 로직이든 추가할 수 있도록 확장성 있게 구현하고 싶었다.
카프카가 메시지를 한 번 소비한다 해도 사라지지 않는다고는 알고 있었는데..
이게 가능할까..? 어떻게 구성해야 되지?? 막막하다...
사실 당연히 분산처리가 가능하다는 건 아래 글을 읽지 않아도 알고 있을 것이다.
(애초에 카프카가 그런 용도로 설계되었는걸요🧐)
그럼에도 이번 기회에 어떻게 가능한지 살펴보자.
우리는 이제 아래 두 가지 조건에 대해 이해하고 있다. (이해하고 있을걸.. 요...?)
1. 카프카는 메시지를 한 번 소비한다 해도 사라지지 않는다.
2. 컨슈머 그룹을 통해서 여러 컨슈머들을 그룹화할 수 있다.
그럼 이제 아래 그림도 이해할 수 있다.

즉 하나의 토픽에 여러 컨슈머 그룹이 연결될 수 있기 때문에 분산 처리가 가능하다는 것이다.
각 컨슈머 그룹과 파티션의 개수를 조정함으로써 성능까지도 문제없이 컨트롤할 수 있다.
그럼 여기서 문제는 각 그룹마다 어떻게 데이터 소비 순서를 관리할까?
그룹이 여러 개가 붙게 되면 각 그룹마다 어떤 데이터를 어디까지 소비했는지 알아야 하는 것 아닌가?
이미 그림에 스포 되어있지만, 각 그룹마다 오프셋을 관리함으로써 이러한 부분을 해결한다.
느낀 점
카프카.. 이제는 백엔드에서 필수 스택이 되어버린 지 오래인 것 같다.
늘 "언젠간 쓰겠지?"라고 생각을 하면서 책도 사고 관심도 가지곤 있었지만, 실전에 사용하진 않았어서 딥하게 공부하진 못했었다.
단순 개념만 알고 있는 정도였기 때문에 조금은 거리감이 있었는데, 급하게 업무에 사용하게 되었다.
근데 내가 사용해보고 싶었던 아키텍처어서 그런지 공부하면서 정말 오랜만에 공부가 재밌다는 느낌을 받았다.
이렇게 책이 술술 읽힌 적도 오랜만이고 이래서 정말 하고 싶은 공부 해야 하는 게 맞는 것 같다. 🤩