
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- Cloud Pub/Sub
- 삼성 SW 역량테스트
- 펜윅 트리
- 그리디
- 이분탐색
- 종만북
- jpa
- 컴퓨터 구조
- REACT
- Air Table
- 다이나믹 프로그래밍
- Cloud Run
- 삼성SW역량테스트
- 생활코딩
- Bit
- 접미사 배열
- 우선순위 큐
- 다익스트라
- JavaScript
- ICPC
- 백준 1753번
- r
- LCS
- BFS
- 수학
- 시뮬레이션
- CI/CD
- 고속 푸리에 변환
- dp
- 데이터 분석
- Today
- Total
코딩스토리
Chapter 3. 명령어 집합 본문
# 본 내용은 한국항공대학교 길현영 교수님의 '컴퓨터 구조' 강의 및 컴퓨터 아키텍처(우종정, 한빛 아카데미)를 바탕으로 작성한 글입니다.
1. 명령어 집합 구조
우리는 HLL(High Level Language)를 통해 프로그램을 작성한다.
앞에서도 살펴봤듯이 컴퓨터는 HLL을 바로 이해하는 게 아니라 기계어로 변환 과정이 필요하다.
이 기계어를 명령어라고 볼 수 있다. (기계 명령어 = 기계어 = 명령어)
명령어 집합 구조는 좁은 의미의 컴퓨터 구조를 말한다.
즉 ISA(명령어 집합 구조)는 어떤 프로그램과 그 프로그램을 수행할 컴퓨터 하드웨어 사이의 인터페이스에 대한 완전한 정의 혹은 명세이다.
이때 ISA는 컴퓨터 하드웨어가 수행할 수 있는 모든 명령어에 대해 아래와 같은 내용을 명시한다.
- 컴퓨터 하드웨어가 어떤 연산을 수행할 수 있고, 각 연산에 어떤 데이터가 필요한지를 명시한다.
- 사용할 수 있는 데이터의 표현 방식, 즉 데이터 형식을 명시한다.
- 데이터의 위치에 대한 정보를 알려주는 주소 지정 방식을 명시한다.
ISA에 명시된 연산, 데이터 형식, 주소 지정 방식의 수는 컴퓨터 종류마다 다르다고 한다.
명령어 집합 설계
명령어 집합을 설계하려면 하드웨어 기술이나 컴퓨터 구성, 프로그래밍 언어, 컴파일러 기술, 플랫폼이 될 운영체제 등 컴퓨터와 관련된 많은 사항을 고려해야 한다.
1. 연산의 종류
연산의 종류는 명령어가 프로세서에서 수행할 수 있는 일의 종류를 의미한다.
일반적으로 전송, 처리, 제어, 입출력 4가지 종류의 연산이 있다.
2. 데이터 형식
데이터 형식은 데이터에 가능한 값, 데이터에 실행할 수 있는 명령, 데이터의 의미, 데이터의 값을 저장하는 방식을 의미한다.
즉 데이터의 종류를 명시하고 정수, 실수, 논리와 같은 데이터를 식별하는 분류이다.
3. 명령어 형식
명령어 형식은 명령어 구성 부분을 나타내는 양식을 의미한다.
명령어는 최소한 연산 종류를 지정하는 연산 부호(OP code)를 포함한다.
이 외에도 연산 종류에 따른 피연산자 수와 길이, 종류 등을 나타낼 수 있다.
4. 피연산자의 주소 지정 방식
연산의 종류에 따라 다양한 데이터가 필요하다. 이때 데이터는 cpu 내부의 레지스터에 존재할 수 도 있고, 메모리에 존재할 수 도 있다.
따라서 피연산자인 데이터의 위치를 명시하기 위해 명령어는 주소 지정 방식을 가지고 있다.
명령어의 특성
명령어는 컴퓨터가 수행할 수 있는 동작을 2진수 코드로 정의한 것이다.
명령어는 여러 가지 요소로 구성되는데 중요한 것만 살펴보면
- 연산 부호 : OP code라 하며 컴퓨터가 수행할 연산의 종류를 명시한다.
- 피연산자 필드 : 연산될 데이터를 위한 정보를 포함한다. 대부분 근원지 피연산자와 목적지 피연산자 포함
- 다음 명령어 주소 필드 : 다음 명령어의 위치를 나타내지만 일반적으로는 필요하지 않다.
위 3개의 요소를 중요하다고 한 이유는 앞으로 계속해서 쓰이게 될 것이기 때문이다.
피연산자의 수
z = f( x , y )
위 식은 우리에게 너무 익숙한 식이다.
풀어써보면 f라는 함수는 두 변수 x와 y를 연산한 후 결과값 z를 생성하는 함수이다.
여기서 x, y, z, f를 각각 명령어에 비교할 수 있는데
f를 명령어라 하면, x, y, z는 피연산자라고 할 수 있다. 즉 x, y, z는 데이터의 위치 또는 데이터의 값이 될 수 있다.
이 예시에서는 피연산자가 x, y, z 이렇게 3가지이지만 명령어는 다양한 개수(0,1,2,3)의 피연산자 필드를 가질 수 있다.
(3가지의 피연산자 필드를 갖는 명령어를 3-주소 명령어라고 한다. 대부분의 명령어가 그렇다고 한다.)
간단히 살펴보면
0 주소 명령어 - 스택 사용, 스택의 최상위 2개 데이터 사용하면 됨
1 주소 명령어 - 묵시적 피연산자 사용, ex) Acc = f(Acc, x) 여기서 Acc는 누산기인데, 연산 결과가 Acc에 들어있다 생각하면 편하다.
2 주소 명령어 - 흔히 우리가 코딩할 때 쓰는 x += y와 같은 것이다.
명령어의 길이
이제 명령어가 일반적으로 연산 부호(OP code)와 피연산자로 구성되어 있음을 알았다.
또 피연산자가 연산의 종류에 따라 달라질 수 있음도 알았다. (0,1,2,3 주소 명령어)
그렇다면 명령어의 길이가 명령어의 종류에 따라 달라질 수 있음도 예상할 수 있다.
명령어는 길이의 특성에 따라 두 가지로 분류한다.
고정 길이 명령어 : 명령어의 종류나 명령어에 포함된 구성요소에 상관없이 명령어의 길이가 모두 일정
길이가 고정되어 있다면 모든 명령어가 길이가 같다는 말이다.
즉 컴퓨터는 명령어를 해독할 때 같은 길이의 명령어만 해독하면 되므로 용이하다는 것이다.
하지만 단점은 굳이 길지 않아도 되는, 짧은 길이의 명령어들도 길이가 길어질 수 있으므로 프로그램의 크기가 증가하게 된다는 것이다.
가변 길이 명령어 : 명령어의 종류나 명령어에 포함된 구성요소에 따라 다양한 길이의 명령어 사용
몇 개의 피연산자를 가지고 있느냐에 따라 명령어의 길이가 달라질 수 있다.
그렇다면 당연히 명령어의 길이 최적화로 프로그램의 크기가 감소할 것이다.
하지만 각 명령어마다 길이가 다르기 때문에 각각을 처리하는 데 있어서 프로세서 하드웨어 디자인이 어렵다고 한다.
2. CPU의 기본 구성
지금부터 살펴볼 CPU의 기본 구성은 폰 노이만 모델을 기반으로 한다.
아래는 폰 노이만 컴퓨터 모델이다.
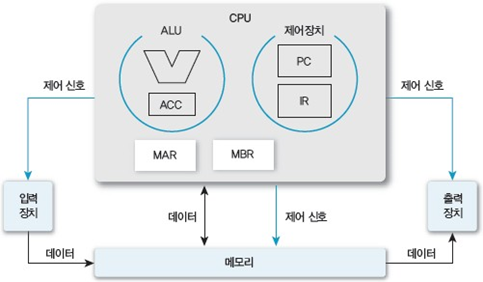
가장 눈에 띄는 점은 CPU와 메모리가 분리되어 있다는 것이다.
각각 구성들을 살펴보자.
먼저 레지스터들이다.
PC (Program Counter) : 다음에 실행할 명령어의 주소를 보관하는 레지스터이다.
IR (명령어 레지스터) : 가장 최근에 인출한 명령어를 보관하는 레지스터이다.
ACC (누산기) : 데이터를 일시적으로 보관하는 레지스터이다.
MAR (메모리 주소 레지스터) : 프로세서가 메모리에 접근하기 위해 참조하려는 데이터 주소를 명시하는 레지스터
MBR (메모리 버퍼 레지스터) : 프로세서가 메모리로부터 읽거나 저장할 데이터 자체를 보관하기 위한 레지스터
( 대부분의 시스템에서 레지스터의 크기는 CPU가 한 번에 처리할 수 있는 데이터 비트 수(word 길이)와 동일)
레지스터 외에도 ALU라는 것을 찾아볼 수 있는데 ALU는 연산 장치로서 각종 산술/논리 연산들을 수행하는 회로들로 이루어져 있다.
이제 어떠한 HW적 요소들이 있는지 알아봤으니 앞에서 공부했던 것들을 좀 더 구체화할 수 있다.
먼저 데이터 적재/저장 과정이다.
적재 과정
1. 프로세서는 데이터가 있는 메모리 주소를 MAR에 보낸다.
2. MAR이 지정하는 메모리 주소에 있는 데이터를 읽어와 MBR에 저장한다.
3. 프로세서는 MBR에 저장된 데이터를 읽는다.
저장 과정
1. 프로세서는 데이터를 저장할 메모리 주소를 MAR에 보낸다.
2. 프로세서는 데이터를 MBR에 저장한다.
3. 메모리는 MAR이 저장하는 위치에 MBR의 내용을 저장한다.
명령어 사이클
1. 인출 사이클
t0 : MAR <- PC # 현재 PC가 가리키는 내용(메모리 주소)을 MAR로 전송
t1 : MBR <- M [MAR], PC <- PC+1 # 메모리는 MAR이 지시하는 메모리의 내용인 명령어를 MBR로 보내고,
PC가 다음 명령어를 가리키도록 PC의 내용을 갱신한다. (여기서 1은 명령어의 길이로 가정)
t2 : IR <- MBR # MBR에 있는 명령어를 IR에 저장
나는 소프트웨어 전공이라 그런지 말로 설명하는 것보다 코드를 보고 이해하는 게 더 쉽다..(교수님 감사합니다)
인출 사이클은 말 그대로 메모리에 있는 명령어를 가져와서 IR에 저장하는 과정을 나타낸 것이다.
2. 실행 사이클 : 인출된 명령어의 연산 부호(OP code)가 의미하는 연산을 수행한다.
조건 분기 명령어
일반적인 HLL에서는 if( x > y )로 표현하고, 과제에서는 Mips 명령어로 beq(branch equal)라고 많이 봤을 것이다.
이렇게 비교하여 생성된 조건을 사용하려면 반드시 저장해둬야 한다.
이때 사용되는 것이 플레그 레지스터이다.
- 올림수(Carry) : 연산 결과에 올림수가 있으면 1, 없으면 0
- 오버플로우(oVerflow) : 연산 결과에 오버플로우가 있으면 1, 없으면 0
- 부호(Sign)/음수(Negative) : 연산 결과가 음수면 1, 양수 혹은 0이면 0
- 영(Zero) : 연산 결과가 0이면 1, 0이 아니면 0
각각은 굳이 설명하지 않아도 실전에서 많이 겪어본 것들이다.
프로시저의 호출과 복귀
프로시저는 특정 작업을 하나의 패키지처럼 수행하기 위한 일련의 명령어를 의미한다.
말은 어려운데 사실 우리는 프로시저를 잘 알고 있다.
아무래도 가장 많이 쓰이는 건 함수일 것이다.
함수같이 프로시저 콜이 생기면, 컴퓨터는 다음 작업을 함수로 가서 할 것이다.
이것이 바로 프로시저의 호출과 복귀 과정이다.
정리해보면,
인출 사이클에서 다음 수행할 명령어를 IR에 저장하고, PC <- PC + 명령어의 길이를 수행한다.
이때 만약 프로시저 콜이 생겼다면,
실행 사이클에서 PC의 값을 TOS(Top of Stack, 스택의 TOP)에 저장한다. (이 과정은 복귀 주소를 저장하는 것이다.)
이유는 프로시저 종료 후 다시 돌아와야 하기 때문에 그 주소를 저장해 놓는 것이다.
이후 PC에 프로시저의 주소를 저장하면 된다.
그럼 다음 명령어 사이클에서는 PC의 값에 따라 프로시저를 수행하러 갈 것이다.
프로시저를 종료한다면 TOS의 내용, 즉 복귀 주소를 PC에 저장하면 된다.
그림으로 보면 이해하기 쉽다. 그냥 함수 호출하는 과정과 똑같다.

여기서 복귀 주소 저장 시 Stack이 아닌 register에 저장한다면?
답은 복귀 주소는 Stack이나 레지스터, 프로시저의 시작 부분에 저장될 수도 있지만 레지스터나 프로시저의 시작 부분에 저장할 경우, 프로시저를 중첩 호출하거나 재진입 가능한 프로시저를 호출할 수 없다고 한다.
(내가 생각한 답은 만약 레지스터에 복귀 주소가 저장된다면 재귀 호출시 복귀 주소를 또 다른 레지스터에 저장해야 될 거고, 또 레지스터에 저장하면 복귀주소를 어떤 레지스터에 저장해놨는지도 저장해야되고..... 반복되면 안그래도 별로 없는 레지스터가 부족할것 같긴 하다. 아닌가..? 정확힌 모르겠네요!)
'컴퓨터구조' 카테고리의 다른 글
| Chapter 6. 연산장치 (0) | 2020.12.05 |
|---|---|
| Chapter 5. 데이터 표현 (0) | 2020.12.03 |
| Chapter 4. 명령어 집합의 분류와 주소 지정 방식 (0) | 2020.12.01 |
| Chapter 2. 컴퓨터의 발전과 성능 (0) | 2020.11.26 |
| Chapter 1. 컴퓨터 시스템의 개요 (0) | 2020.11.25 |



