
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 데이터 분석
- CI/CD
- 접미사 배열
- BFS
- 종만북
- 그리디
- ICPC
- 펜윅 트리
- 다익스트라
- Bit
- 컴퓨터 구조
- 이분탐색
- 다이나믹 프로그래밍
- 생활코딩
- r
- Cloud Run
- 백준 1753번
- Air Table
- Cloud Pub/Sub
- LCS
- REACT
- dp
- 시뮬레이션
- 수학
- 고속 푸리에 변환
- 삼성SW역량테스트
- 우선순위 큐
- jpa
- 삼성 SW 역량테스트
- JavaScript
- Today
- Total
코딩스토리
2 일차 - 데이터 프레임, 데이터 파악 본문
# 이 글을 "Do it! 쉽게 배우는 R 데이터 분석"의 내용을 바탕으로 작성한 글입니다.
데이터 프레임
열 (column) = 속성, value
행 (row) = 정보, case
데이터가 크다 = 행이 많다 or 열이 많다
데이터를 분석하는 입장에서는 열이 많은 것이 더 중요!
Why?
행이 늘어난다 -> 단순히 정보만 늘어난다. 즉 연산 시간만 길어진다.
열이 늘어난다 -> 열이 많아지면 변수가 많아짐 = 조합할 수 있는 경우의 수가 늘어남
데이터 분석은 변수들의 관계를 분석해야 하는데 조합이 늘어난다는 것은 적용하는 분석 기술 고급화
이제 R 스튜디오에서 직접 데이터 프레임을 만들어보자.
코드는 다음과 같다.
# 학생 4명의 영어점수
english <- c(90, 80, 60, 70)
# 학생 4명의 수학점수
math <- c(50, 60, 100, 20)
# 각 학생이 속한 반의 정보
class <- c(1, 1, 2, 2)
# 데이터 프레임 만들기
df_midterm <- data.frame(english, math, class)
# 분석하기
# 영어 성적 평균
mean(df_midterm$english)
# 수학 성적 평균
mean(df_midterm$math)
솔직히 위 코드를 보면 바로 이해가 될 것이다. 딱히 어려운 스킬 같은 건 없다.
R.. 보면 볼수록 마음에 드는 언어이다. 깔끔 그자체
그래도 새로운 걸 배웠으니 잠시 살펴보면
data.frame(변수, 변수,..)를 통해 데이터 프레임을 생성해 줄 수 있음을 알 수 있다.
또한 '$' 연산자를 통해 데이터 프레임의 각 열에 접근할 수 있음을 알 수 있다.

외부 데이터 사용하기
당연한 이야기이지만 우리가 직접 데이터를 입력해서 분석하는 일은 많이 없다.
그렇기에 외부에서 생성된 데이터를 불러와 분석하는 방법을 알아야 한다.
데이터를 관리할 때에는 엑셀 파일과 CSV 파일이 가장 많이 사용된다고 한다.
먼저 excel 파일을 git에서 다운받았다. (해당 파일을 프로젝트 폴더로 옮겨줌)
그리고 아래와 같은 코드를 통해 readxl 패키지를 다운받아 사용해야 한다.
install.packages("readxl")
library(readxl)
파이썬의 import 같은 느낌이다.
이제 실제로 엑셀 파일을 불러와보면

요런 식으로 엑셀의 데이터를 가져올 수 있다.
여기서 눈여겨볼 점은 자동으로 data frame 형태가 된다는 점이다.
엑셀 파일을 불러올 때 주의해야 할 점이 있다.
read_excel() 함수는 엑셀 파일의 첫 번째 행을 변수 명으로 인식해 불러온다.
만약 데이터가 변수 명 없이 바로 시작되는 경우 첫 번째 행의 데이터를 사용하지 않게 된다.
이런 경우를 대비하여 read_excel()에 인자로 col_names = F를 주면, 변수명을 자동으로 '숫자'로 만들어주고 첫 번째 행부터 데이터를 정상적으로 입력받아온다.
df_exam <- read_excel("excel_exam.xlsx", col_names = F)
여기서 F란 False를 의미하는 것으로 R 언어에서도 bool 타입 변수가 있음을 알 수 있다.
R에서는 이러한 타입을 논리형 벡터 (Logical Vectors)라고 부른다고 한다.
이번엔 CSV 파일을 불러와보자.
먼저 CSV 파일을 이번에 처음 만나보는데
쉼표로 구분된 데이터들로 엑셀 파일에 비해 용량이 적어 데이터를 주고받을 때 많이 사용한다고 한다.
csv 파일을 git에서 내려받고 프로젝트 폴더에 저장해준다.
(이때 확장자를 txt에서 csv로 바꿔주고, 파일 형식도 모든 파일로 변경해줘야 함!)
csv 파일을 R 스튜디오에 불러오는 코드는 다음과 같다.
df_csv_exam <- read.csv("csv_exam.csv")
별도의 패키지를 다운 받을 필요 없이 내장 함수로 바로 불러올 수 있다.
csv 파일도 마찬가지로 첫 번째 행이 변수명이 아닐 때 대처하는 방법이 존재한다.
인자명만 header로 바꿔주면 동일하게 사용할 수 있다.
df_csv_exam <- read.csv("csv_exam.csv", header = F)
또한 csv 파일에 문자가 들어있다면 아래와 같이 처리해줘야 정상적으로 불러올 수 있다.
df_csv_exam <- read.csv("csv_exam.csv", stringsAsFactors = F)
자 이제 불러오는 방법을 알았으니 내보내는 방법도 알아야겠죠?
개인적인 사담이지만
파일을 불러오고 내보내는 작업은 다른 언어에서 코드를 사용할 때도 굉장히 어려웠다..
C언어에서도 그렇고 python, 특히 JAVA 수업 때 등등...
왜 그런지 모르겠는데 파일 입출력 같이 '파일'이 들어간 연산은.. 끔찍해
근데 R은 너무 간단하네?
자꾸 R에 호감도가 높아진다.
다시 돌아와서
csv 파일을 저장해보자.
코드는 다음과 같다.
df_midterm <- data.frame(english = c(90, 80, 60, 70),
math = c(50, 60, 100, 20),
class = c(1, 1, 2, 2))
df_midterm
write.csv(df_midterm, file = "df_midterm.csv")
여기서 내가 설명해야 하는 부분이 없다.
너무너무너무 간단하다.
뭐 잠깐 보자면 수학 점수가 영어 점수에 비해 매우 낮다는 점?
이거 말고는 딱히...
실제로 프로젝트 파일에 저장되어 있는지 확인해보자.

오..
판타스틱하다.
지금이 오전 3시 30분인 것도 확인할 수 있다.
(밤낮이 제대로 바껴버렸다..
아니 Shake 대회 끝나고 기절했는데 새벽에 일어나는 거 실화냐고..)
다음은 RDS 파일이다.
이것도 처음 들어보는 파일 이름인데
R 전용 데이터 파일이라고 한다.
다른 파일들에 비해 R에서 읽고 쓰는 속도가 빠르고 용량이 적다고 한다.
saveRDS(df_midterm, file = "df_midterm.rds")
이것도 내장 함수인 saveRDS를 사용하여 쉽게 가능하다.
이제 저장된 RDS 파일을 불러와보자.
rm(df_midterm) # 기존에 저장되어 있는 df_midterm를 삭제
df_midterm <- readRDS("df_midterm.rds")
df_midterm
rm() 이란 함수를 통해 변수를 제거해주고
readRDS()를 통해 불러온다.

깔끔 그 자체.
이제 데이터를 불러오고 내보낼 수 있으니, 본격적으로 데이터를 분석해보자.
데이터를 파악할 때에는 다음과 같은 함수들을 사용한다고 한다.
| 함수 | 기능 |
| head() | 데이터 앞부분 출력 |
| tail() | 데이터 뒷부분 출력 |
| View() | 뷰어 창에서 데이터 확인 |
| dim() | 데이터 차원 출력 |
| str() | 데이터 속성 출력 |
| summary() | 요약 통계량 출력 |
뭐.. 이렇게만 보면 잘 이해가 안 가는 게 당연하다.
이제 R 스튜디오에서 직접 해보자.
내가 사용하려는 데이터는 다음과 같다.

이제 각각의 함수를 실행시켜보자.
1. head() 함수

함수의 설명대로 데이터의 앞부분 중 일부분을 출력했다.
인자를 입력하지 않았을 경우 앞에서부터 6행을 출력해주고, 인자를 입력하면 그만큼 출력해준다.
2. tail() 함수

tail 또한 head와 마찬가지이다.
설명은 생략한다.
3. View() 함수
조금 특이한 함수인데 함수 명대로 엑셀과 유사한 데이터 뷰어 창에서 데이터를 직접 보여준다.
원자료를 직접 눈으로 확인해보고 싶을 때 사용한다고 한다.

4. dim() 함수
데이터가 몇 행, 몇 열로 구성되어있는지 반환한다.
이름 맹키로 dimension -> 차원을 출력해준다.

이로써 exam 데이터는 20행 5열로 이루어져 있음을 알 수 있다.
5. str() 함수
데이터에 들어있는 변수들의 속성을 보여 준다.

각각이 뭘 뜻하는지는 쉽게 알 수 있다.
6. summary() 함수
설명에는 '요약 통계량 산출'이라고 적혀 있으나 바로 감이 오지는 않으니 한번 코드로 살펴보자.

음...
각 변수들에 대해 뭐가 막 쓰여있다.
min과 max, mean 이 뭔지는 알겠는데... 다른 것들은.. 내가 영어를 잘 못해서 ㅎㅎ
책에는 아주 잘 설명되어있다. 모르는 3가지만 적어보자면 다음과 같다.
| 출력값 | 통계량 | 설명 |
| 1st Qu | 1사분위수(1st Quantile) | 하위 25%(4분의 1) 지점에 위치하는 값 |
| Median | 중앙값(Median) | 중앙에 위치하는 값 |
| 3st Qu | 3사분위수(3rd Quantile) | 하위 75%(4분의 3) 지점에 위치하는 값 |
또 한 번 짝짝짝짝짝!!!
이 얼마나 간편한 언어인가!
근데 사실 여기서 살짝 궁금증이 생겼다.
실행 결과를 잘 보면 english의 Median = 86.5이다.
왜..? 모든 사람들의 english 변수 값은 정수인데 왜 소수점이 생기지?
중앙값은 말 그대로 중앙값 아닌가?
여기서부터 혼란이 오기 시작했다.
책에서는 다음과 같이 설명하고 있다.
(수학 점수를 예로 들면)
학생들의 수학 점수가 54점(Median)을 중심으로 45.75점에서 75.75점 사이 (1st Qunatiole, 3rd Quantile)에 몰려있다!
음..
한번 배웠던 걸 응용해볼까?
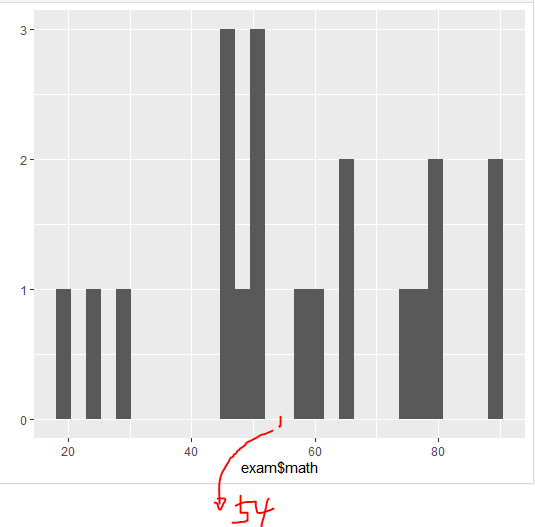
1일 차 때 공부했던 qlot()을 사용하여 나타내 보았다.
Median 값(54)을 기준으로 각각 10개씩 나눠져 있음을 알 수 있다.
이제야 중앙값의 정의가 이해되었다.
이제 앞으로 이런 기본적인 함수들을 통해 데이터들의 전반적인 특징을 파악할 수 있게 되었다.
변수명 바꾸기
변수명은 정말 중요하다.
따른 프로그래밍에서도 변수명은 정말 정말 중요하다.
(방금까지 알고리즘 문제를 풀고 있었는데 변수명.. 정말 중요하다...
코드가 100줄이 넘어가고 함수가 4, 5가 나오는 순간부터는 변수명 때문에 오류를 못 찾는 경우가 생길 수 있다...
경험담이에요ㅠ.. 지금 살짝 멘탈이 나가서ㅎ)
변수명은 dplyr 패키지의 rename() 함수를 통해 변경 가능하다.
install.packages("dplyr")
library(dplyr)
df_raw <- data.frame(var1 = c(1,2,1),
var2 = c(2,3,2))
df_raw <- rename(df_raw, changeV2 = var2)
df_raw

코드는 어렵지 않다.
변수 명도 정상적으로 바뀐 것을 볼 수 있다.
주의할 점은 rename의 인자다.
변경 후의 변수명 = 변경 전의 변수명이다.
파생 변수 만들기
파생이란 말 정말 많이 들어봤다.
파생 변수란 이름 그대로 다른 변수에서 파생된 변수이다.
즉, 기존의 변수를 변형해 새로운 변수를 만든다는 것이다.
예를 들어 보면 국어, 영어 점수 변수가 있다면 파생 변수로 평균 점수를 만들 수 있다.
바로 코드로 확인해보자.
df <- data.frame(math = c(60, 70, 80),
english = c(100, 80, 90))
df$eval <- (df$math + df$english)/2
df

수학과 영어 점수를 통해 eval 이란 변수를 새롭게 생성해 냈다.
자 이제 변수를 어느 정도 다룰 줄 알았다면 뭐를 공부할까?
대부분의 언어는 100이면 100 조건문에 대해 공부할 것이다.
조건문을 통해 파생 변수를 생성해보자.
내가 짤 코드는 평균 점수를 통해 PNP를 가려내는 코드이다.
df <- data.frame(math = c(60, 70, 80, 30),
english = c(100, 80, 90, 40),
korean = c(50, 30, 60, 50))
df$mean <- (df$math + df$english + df$korean)/3
df$PNP <- ifelse(df$mean >= 70, "PASS", "N-PASS")
df

크...
알고리즘 풀다가 R 공부하니까 천국이 따로 없다
df$PNP <- ifelse(df$mean >= 70, "PASS", "N-PASS")
이 코드를 통해 PNP 변수를 새로 생성해준다.
ifelse라는 조건문은 눈여겨볼 필요가 있다.
(c언어의 ? : 구문과 유사하다.)

library(ggplot2)
qplot(df$PNP, df$mean)
이 코드를 통해서 그래프로 표현해 보았다.
당연히 중첩 조건문도 가능하겠죠?
df$grade <- ifelse(df$mean >=70, "A",
ifelse(df$mean>=50, "B", "C"))

등급도 나눠 보았다.
여기까지 2일 차 공부였다.
아직까진 말 그대로 기초여서 순탄하지만 앞에 어떤 게 있을지.. 슬슬 무서워지기 시작한다.
그래도 아직까진 R 너무 좋아~
'데이터 분석' 카테고리의 다른 글
| 5 일차 - 그래프 만들기 (0) | 2021.01.28 |
|---|---|
| 4 일차 - 데이터 정제 (0) | 2021.01.27 |
| 3 일차 - 데이터 가공 (0) | 2021.01.26 |
| 1 일차 - R 기초 (2) | 2021.01.22 |
| 데이터 분석 계획표 (0) | 2021.01.22 |


