
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 수학
- Cloud Pub/Sub
- 데이터 분석
- r
- LCS
- 우선순위 큐
- 다익스트라
- 다이나믹 프로그래밍
- 이분탐색
- 시뮬레이션
- Air Table
- 접미사 배열
- 삼성 SW 역량테스트
- ICPC
- 생활코딩
- Bit
- REACT
- 그리디
- 삼성SW역량테스트
- Cloud Run
- 종만북
- 컴퓨터 구조
- dp
- 펜윅 트리
- 고속 푸리에 변환
- CI/CD
- BFS
- jpa
- JavaScript
- 백준 1753번
- Today
- Total
코딩스토리
3 일차 - 데이터 가공 본문
# 이 글을 "Do it! 쉽게 배우는 R 데이터 분석"의 내용을 바탕으로 작성한 글입니다.
데이터 전처리
데이터를 분석에 적합하게 가공하는 작업을 데이터 전처리라고 한다.
dplyr 패키지는 앞에서도 공부했지만 데이터 전처리 작업에 가장 많이 사용되는 패키지라고 한다.
| dplyt 함수 | 기능 |
| filter() | 행 추출 |
| select() | 열(변수) 추출 |
| arrange() | 정렬 |
| mutate() | 변수 추가 |
| summarise() | 통계치 산출 |
| group_by() | 집단별로 나누기 |
| left-join() | 데이터 합치기(열) |
| bind_rows() | 데이터 합치기(행) |
바로 코드로 하나씩 살펴보자.
1. filter() 함수
library(dplyr)
exam <- read.csv("csv_exam.csv")
exam
exam %>% filter(class == 1)
exam 데이터는 다음과 같다.

잘 보면 클래스는 1~5까지로 이루어져 있다.
위의 코드를 통해 클래스가 1인 데이터들을 뽑아낼 수 있다.

코드에서 주의할 점은 "%>%" 연산자이다.
파이프 연산자라고 읽으며 함수들을 연결하는 기능을 한다. (단축키 : Ctrl + Shift + M)
이건 처음보는데..
뭐 이런 건 이해하기보단 암기가 당연하니까! PASS~
filter() 함수는 딱 봐도 쓰임새가 많을 것 같다.

당연히 매개변수를 무엇을 주냐에 따라 다양하게 사용이 가능하다.
아래의 코드를 보자.
exam %>% filter(class %in% c(1,3,5))
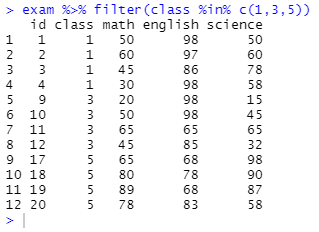
%in% 연산자가 새롭게 등장했다.
해당 코드는 "1, 3, 5 반에 속한 데이터를 필터링해줘"라는 것이다.
%in% 연산자는 매치 연산자라고 읽으며 변수의 값이 지정한 조건 목록에 해당하는지 확인한다.
2. select() 함수
select()는 일부 변수만 추출해 활용하고자 할 대 사용한다.
exam %>% select(class, math)

추가적으로 변수를 제외하고 출력하는 기능도 가능하다.
exam %>% select(-math)
이제 filter()와 select()를 알았으니 아래 코드를 보자.
exam %>%
filter(class == 1) %>%
select(math)
이렇게 dplyr 패키지의 함수를 조합하여 사용도 가능하다.
(위의 코드는 class = 1 인 행 중에서 math 점수만 추출한 것이다.)
filter()와 select()는 헷갈릴 수 있으니 꼭 기억하자.
3. arrange() 함수
arrange() 함수는 데이터를 정렬시켜준다.
exam %>% arrange(math) %>% head(5)

exam 데이터들 중 math 성적을 오름차순으로 정렬하였다.
이때 head(5)는 앞에서 5번째까지만 출력하겠다는 이야기이다.
내림차순도 굉장히 간단하다.
exam %>% arrange(desc(math)) %>% head(5)해당 변수를 desc()로 감싸주기만 하면 된다.
4. mutate() 함수
앞에서 파생변수에 대해서 공부했었다.
mutate() 함수는 파생변수를 만들어 추가하는 함수이다.
exam %>% mutate(eve = (math + english + science)/3 )

역시 파생 변수를 이해하고 있다면 어려운 코드는 아니다.
아.. R 너무 좋아..
그럼 이제 앞에서 배운 함수들을 응용해보자.

보면 아주 간단하다.
eve라는 평균점수를 담은 파생변수를 만들어 데이터에 추가시키고,
eve에 대해 오름차순으로 정렬한 뒤
앞에서 6번째 데이터 까지만 출력한 것이다.
간단하죠~
5. group_by()와 summarise() 함수
이 두 함수는 집단별 평균이나 집단별 빈도처럼 각 집단을 요약한 값을 구할 때 사용한다.
먼저 summarise()부터 살펴보자.

직관적으로 이해가 가능하다.
대신 데이터에 추가시켜주는 것(파생 변수)이 아니라 요약해서 출력해주는 것이라는 점!
이제 group_by()와 조합해서 사용해보자.
exam %>%
group_by(class) %>%
summarise(mean_math = mean(math))

오,, 신기하다.
group_by(class)란 코드를 통해 데이터를 클래스 별로 묶어주고,
summarise 함수를 통해 math 성적의 평균을 구해서 출력해 준다.
여기서 tibble : 5*2 란 데이터가 5행 2열의 tibble 형태라는 것을 알려주는 것이고, tibble은 데이터 프레임의 업그레이드? 버전이라고 한다.
int 가 뭔지는 굳이.. dbl 도 뭔지는.. 넘어가자
지금까지 배운 함수들을 전부 응용해서 데이터를 출력해보자.
exam %>%
group_by(class) %>% # 각 반별로 분리
filter(math >= 50) %>% # 수학 성적이 50점 이상인 학생들 중
mutate(sum = math + english + science) %>% # 각 학생들의 성적 총합 변수 생성
summarise(elite = sum/3) %>% # 평균 성적에 대해 요약
arrange(desc(elite)) %>% # 평균 성적이 높은 순으로 출력
head

확실히 내가 생각해내서 출력하려니 어렵긴 하다..
그래도 어찌 저지 내 맘대로 조건을 생성해서 출력을 해 보았다.
설명해보자면
1. 각 반별로 분리한 뒤
2. 수학 성적이 50점 이상인 학생들만 구하고
3. 해당 학생들의 성적 총합을 구해 sum이란 파생변수를 만든 뒤
4. 총점의 평균을 구해 각 학생들의 평균 성적을 구해서 출력할 것인데
5. 내림차순, 즉 성적이 좋은 elite부터 뽑겠다
라는 코드이다.
지금 보니 굳이 반별로 분리할 필요까진 없었을 듯한데 아직 이해도가 부족하여 그런 듯하다.
어쨌든 이렇게 데이터를 가지고 놀아보았다.
추가적으로 데이터를 합치는 함수에 대해 알아보자.
데이터를 가로로 합치거나 세로로 합치는 것이 가능하다.
1) 가로로 합치기
test1 <- data.frame(id = c(1,2,3,4,5),
math = c(50,60,70,80,90))
test2 <- data.frame(id = c(1,2,3,4,5),
english = c(70,80,90,90,80))
total <- left_join(test1, test2, by = "id")
total

1~5번의 학생들의 수학 점수와 영어 점수를 각각의 data frame이 가지고 있다면
left_join을 통해 합칠 수 있다.
응용해본다면 해당 학생들의 이름이 담긴 data frame도 더해줄 수 있다.

2) 세로로 합치기
가로로 합치기의 다른 버전이라고 생각하면 편하다.

굉장히 간단하다.
세로로 합칠 때에는 변수명이 같아야 한다.
만약 다르다면 앞에서 배웠던 rename() 함수를 통해 변수명을 바꿔준 뒤 합쳐주면 깔끔!
오늘도 R을 배우며 행복하게 코딩 중이다.
언제까지 이 행복함이 유지될진 모르겠지만 그래도 R 최고!
'데이터 분석' 카테고리의 다른 글
| 5 일차 - 그래프 만들기 (0) | 2021.01.28 |
|---|---|
| 4 일차 - 데이터 정제 (0) | 2021.01.27 |
| 2 일차 - 데이터 프레임, 데이터 파악 (0) | 2021.01.24 |
| 1 일차 - R 기초 (2) | 2021.01.22 |
| 데이터 분석 계획표 (0) | 2021.01.22 |



