
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- BFS
- jpa
- 우선순위 큐
- 펜윅 트리
- Air Table
- ICPC
- 컴퓨터 구조
- 시뮬레이션
- 고속 푸리에 변환
- 다이나믹 프로그래밍
- 데이터 분석
- r
- 백준 1753번
- 접미사 배열
- 삼성 SW 역량테스트
- CI/CD
- REACT
- Cloud Run
- Cloud Pub/Sub
- 종만북
- LCS
- JavaScript
- dp
- 다익스트라
- 이분탐색
- 수학
- 생활코딩
- 그리디
- 삼성SW역량테스트
- Bit
- Today
- Total
코딩스토리
9 일차 - 텍스트 마이닝 본문
# 이 글을 "Do it! 쉽게 배우는 R 데이터 분석"의 내용을 바탕으로 작성한 글입니다.
텍스트 마이닝이란 문자로 된 데이터에서 가치 있는 정보를 얻어 내는 분석 기법이다.
해당 분석을 하기 위해 가장 먼저 해야할 일은 '형태소 분석'이다.
즉 문장을 구성하는 어절들이 어떤 품사로 되어 있는지 파악하는 것이다.
이후 각 품사의 단어들을 추출해 등장 횟수를 체크한다.
오늘도 책을 따라 분석을 시작해보자.
1. 힙합 음악 가사 텍스트 마이닝
먼저 한글 자연어 분석 패키지인 KoNLP를 사용해야 한다.
이 패키지를 사용하려면 Java가 깔려있어야 한다고 하니 참고하고 설치 방법은 책을 사서 확인하길..
이런 게 제일 짜증 난다 패키지 설치하고 뭐 다운받고 등등...
이거 다운받는것도 쉽지 않았다..ㅠ
거의 1시간 만에 드디어 데이터를 다 다운받고 본격적인 분석을 할 준비를 마쳤다.
지금 코드포스를 본 뒤 새벽 2시 반인데 진짜 졸려 죽을 것 같으니까 일어나서 다시 하자..
오.. hiphop 가사라길래 한번 쓰윽 봤는데 어디서 많이 본 가사들이 보인다?
2017년 3월 멜론 차트 노래 가사들이라고 한다.
하.. 2017년... 넘어가자
먼저 특수문자들부터 전부 제거해보자.
install.packages("stringr")
library(stringr)
txt <- str_replace_all(txt, "\\W", " ") # 특수문자(정규식) 지우기
이제부터의 코드들은 딱히 설명할 코드들이 별로 없다.
어차피 패키지의 라이브러리에 있는 함수들을 사용하고, 매우 직관적이기 때문에 어떤 일을 하는지만 간단히 코드와 함께 살펴보자.
1. 명사 추출하기
말 그대로 명사를 추출해서 빈도수를 확인한다.
install.packages("stringr")
library(stringr)
library(KoNLP)
library(dplyr)
txt <- readLines("hiphop.txt")
txt <- str_replace_all(txt, "\\W", " ") # 특수문자(정규식) 지우기
# 가사에서 명사 추출하기
nouns <- extractNoun(txt)
# 추출한 명사 list를 문자열 벡터로 반환, 단어별 빈도표 생성
wordcount <- table(unlist(nouns))
# 데이터 프레임으로 변환
df_word <- as.data.frame(wordcount, stringsAsFactors = F)
# 변수명 수정
df_word <- rename(df_word,
word = Var1,
freq = Freq)
# 두 글자 이상 단어 추출 (한 글자는 의미 없는 경우 많음! ex) 싶다-> 싶)
df_word <- filter(df_word, nchar(word) >= 2)
top_20 <- df_word %>%
arrange(desc(freq)) %>%
head(20)
top_20
한 글자 명사들을 제거하지 않으면 다음과 같은 일이 벌어진다.

2글자 이상 단어만 정상적으로 출력해보면 다음과 같다.

음.. 생각보다 사랑, love가 많지가 않네? 랩이랑 힙합이라 그런가
갑자기 나중에 발라드 가사들도 해보고 싶은 생각이 들었다.
이 정도도 물론 분석이라고 할 수 있지만 그래프로 나타내는 것처럼 데이터의 시각화도 중요하다.
텍스트 마이닝의 꽃, 워드 클라우드를 만들어보자.
2. 워드 클라우드
워드 클라우드란 말 그대로 단어 구름, 단어의 빈도를 구름 모양으로 표현한 그래프이다.
각 단어의 빈도에 따라 색깔과 크기가 다르게 표현되기 때문에 어떤 단어가 얼마나 많이 사용됐는지 한눈에 파악 가능하다.
당연히 wordcloud 패키지를 설치하고 필요한 라이브러리를 불러온다.
그리고 아래와 같은 코드들을 통해 워드 클라우드를 생성한다.
# Dark2 색상 목록에서 8개 색상 추출
pal <- brewer.pal(8,"Dark2")
# wordcloud() 함수는 실행할 때마다 다른 모양 만들어냄
# 따라서 난수를 고정함으로써 항상 같은 모양 만들어내기
set.seed(1107)
# 워드 클라우드 만들기
wordcloud(words = df_word$word, # 단어
freq = df_word$freq, # 빈도
min.freq = 2, # 최소 단어 빈도
max.words = 200, # 표현 단어 수
random.order = F, # 고빈도 단어 중앙 배치
rot.per = .1, # 회전 단어 비율
scale = c(4,0.3), # 단어 크기 범위
colors = pal) # 색상 목록
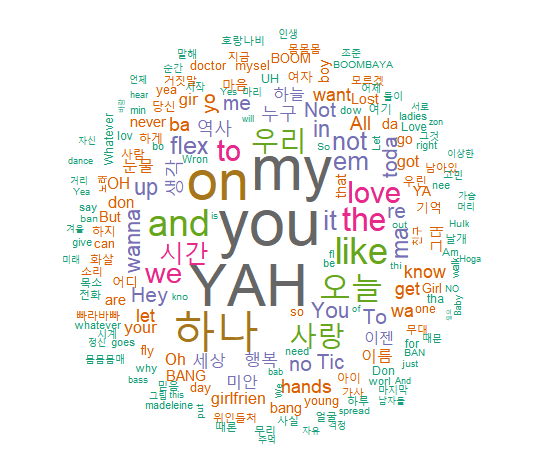
WOWOWOWOWOW!
너무 이쁘다ㅠㅠㅠ
나도 이제 이런 걸 만들 수 있다니ㅠㅠ
사실 책에 있는 코드 그냥 그대로 따라친거밖에 없고, 완벽한 결과물도 아니지만 그래도 뭔가 벽?을 뿌순 느낌이다.
다른 예제들은 내가 직접 만들어보고 git_hub에 올려놓으면 좋을 것 같다.
이렇게 하나하나 배워가는 느낌이 참 좋다. 물론 많이 어렵지만^^
코드는 아래 링크에 올려놓았다.
github.com/kimtaehyun98/Data_Analysis_TextMining
kimtaehyun98/Data_Analysis_TextMining
Do it! 쉽게 배우는 R 데이터 분석 9장 - 힙합 가사 텍스트 마이닝. Contribute to kimtaehyun98/Data_Analysis_TextMining development by creating an account on GitHub.
github.com
'데이터 분석' 카테고리의 다른 글
| 11 일차 - 인터랙티브 그래프 (2) | 2021.02.19 |
|---|---|
| 10 일차 - 지도 시각화 (0) | 2021.02.08 |
| 8 일차 - 데이터 분석 프로젝트 3 (0) | 2021.02.03 |
| 7 일차 - 데이터 분석 프로젝트 2 (0) | 2021.02.01 |
| 6 일차 - 데이터 분석 프로젝트 1 (0) | 2021.01.30 |



