
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- r
- 그리디
- BFS
- Bit
- REACT
- Cloud Pub/Sub
- dp
- 접미사 배열
- CI/CD
- 고속 푸리에 변환
- 컴퓨터 구조
- 종만북
- 펜윅 트리
- 삼성SW역량테스트
- 다익스트라
- 이분탐색
- 다이나믹 프로그래밍
- jpa
- 삼성 SW 역량테스트
- 수학
- 시뮬레이션
- 우선순위 큐
- LCS
- 데이터 분석
- JavaScript
- Air Table
- ICPC
- Cloud Run
- 생활코딩
- 백준 1753번
- Today
- Total
코딩스토리
7 일차 - 데이터 분석 프로젝트 2 본문
# 이 글을 "Do it! 쉽게 배우는 R 데이터 분석"의 내용을 바탕으로 작성한 글입니다.
어제에 이어 데이터 분석을 해보자.
기본적인 내용은 6일 차와 같다.
6 일차 - 데이터 분석 프로젝트 1
# 이 글을 "Do it! 쉽게 배우는 R 데이터 분석"의 내용을 바탕으로 작성한 글입니다. 드디어 본격적인 데이터 분석 프로젝트를 시작한다. 내가 분석할 데이터는 '한국 복지패널데이터'이
kimtaehyun98.tistory.com
1. 연령대에 따른 월급 차이
"어떤 연령대의 월급이 가장 많을까?"라는 질문에 데이터 분석을 통해 답해보자.
어제 birth 변수를 사용해 새로운 파생 변수 age를 생성했다.
이제 이 age 변수를 통해 연령대를 나타내는 'age_group'이라는 새로운 변수를 생생해보자.

mutate() 함수는 앞에서 설명했기 때문에 넘어간다.
공부했던 것들을 자유자재로 사용하는 건 아직 무리인 거 같다..
이제 연령대 변수를 생성했으니 월급 변수를 생성해보자.
생각해보니 월급 변수는 이미 있구나..?
그럼 바로 두 변수의 관계를 분석해보자.

몇 번 해봤으니 간단하게 설명해보면
filter() 함수를 통해 결측치를 제외하고
연령대별로 묶은 뒤
평균 월급으로 요약한다.
이제 그래프로 출력해보면
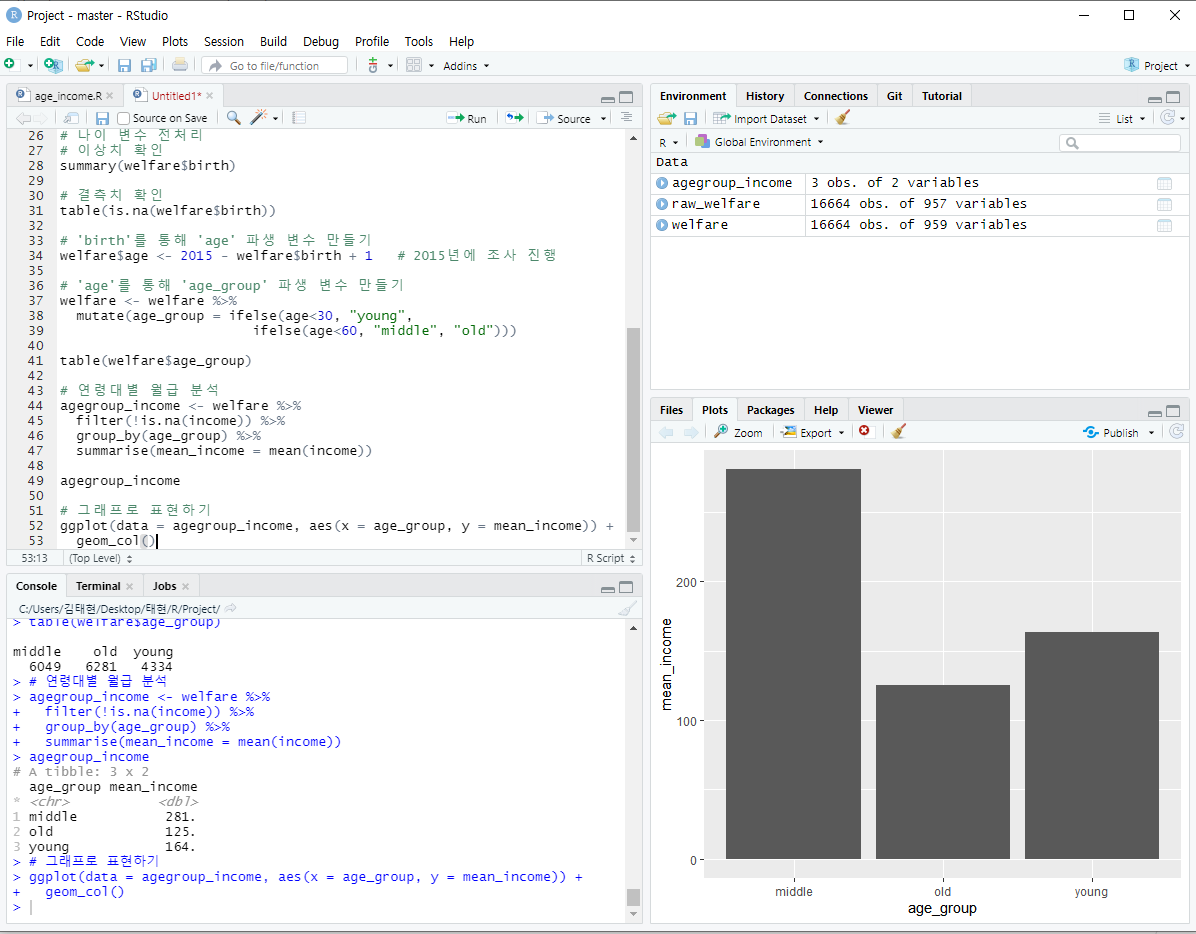
그래프를 조금 더 깔끔하게? 확인하기 위해 young -> middle -> old 순으로 정렬해보자.
# 그래프로 표현하기
ggplot(data = agegroup_income, aes(x = age_group, y = mean_income)) +
geom_col() +
scale_x_discrete(limits = c("young", "middle", "old"))
# young -> middle -> old 순으로 정렬!

전체 코드는 아래의 git hub에 올려놓았다.
2. 연령대 및 성별 월급 차이
이제부터 조금 어려워진다.
앞에서는 두 개의 데이터 만으로 분석을 진행했다.
하지만 이번에는 제목에서만 봐도 알겠지만 '연령대', '성별', '월급' 이 세 가지 변수가 필요하다.
"성별 월급 차이는 연령대별로 다를까?"라는 질문에 답해보자.
# 성별에 따른 각 연령대별 월급 차이 분석
age_sex_income <- welfare %>%
filter(!is.na(income)) %>% # 결측치 제거
group_by(age_group, sex) %>% # 각 연령대를 성별로 나눔
summarise(mean_income = mean(income)) # 월급의 평균
자꾸자꾸 까먹는다..
계속해서 책을 다시 보고 있다...ㅠ
R언어 자체가 어렵진 않지만 아무래도 기초 지식이 꽤 필요한 것 같다.
어쨌든 위의 코드를 통해 성별에 따른 각 연령대별 월급 변수를 생성했다.
이제 그래프로 나타낼 차례이다.
ggplot(data = age_sex_income, aes(x = age_group, y = mean_income, fill = sex)) +
geom_col() +
scale_x_discrete(limits = c("young", "middle", "old"))새로운 코드가 나와서 가져와봤다.
fill = sex를 통해 색깔을 성별로 나타낼 수 있다.

내가 만들었던 그래프 중에 가장 이쁜 것 같다ㅎㅎ
근데 이렇게 보면 살짝 헷갈린다.
female의 값이 male값 위에 올라가 있어 female의 정확한 비교가 힘들다.
그럼 바꿔줘야겠지요
geom_col(position = "dodge")geom_col의 인자만 바꿔주면 깔끔!

오.. 생각보다 중년일 때 남성과 여성의 월급 차이가 많이 나네요...
전체 나이에 대해 분석도 같이 해보았다.
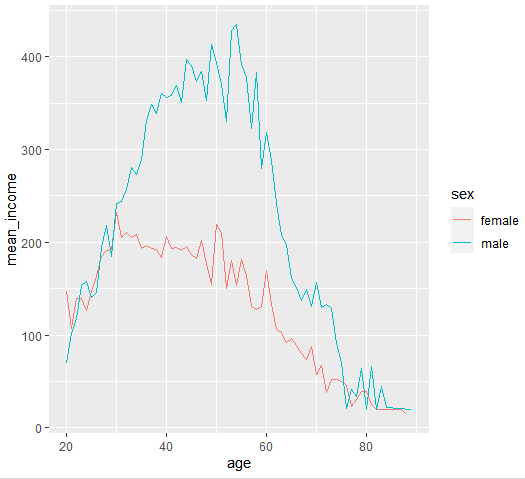
코드는 거의 비슷하기 때문에.. 넘어간다.
바로 다음으로 넘어가 보자!
3. 직업별 월급 차이
"어떤 직업이 월급을 가장 많이 받을까?"
이 질문의 답은 나도 굉장히 궁금하다.
이제 바로 데이터 분석을 통해 답을 찾아내 보자.
데이터엔 직업이 code_job 이란 변수에 담겨있다.
한번 출력해보자.

어.. 결측치도 많고 알 수 없는 숫자들로 이루어져 있다.
사실 앞 포스팅에서 언급했던 code book을 살펴보면 왜 그런지 알 수 있다.
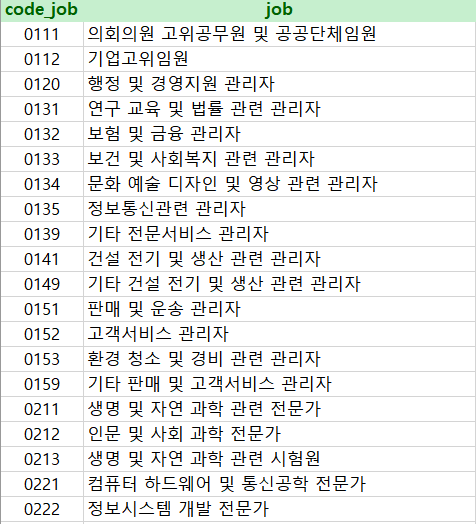
전부 캡처한 화면이 아니다.
즉 어마 무시하게 많다.
저걸 언제 다 옮겨 쓰지..?라고 생각했다면 바보다.
물론 나도 바보다.
앞에서 데이터 합치기를 배웠잖아!!!!
그럼 이제 저 코드북의 데이터를 가져와보자.

잘 보면 어떻게 합쳐야 할지 감이 올 것이다.
code_job이란 변수가 여기도 있네?
바로 합쳐보자.
# codebook에서 직업 코드 가져오기
list_job <- read_excel("Koweps_Codebook.xlsx", col_names = T,sheet=2)
# left_join 함수를 통해 list_job과 합치기
welfare <- left_join(welfare, list_job, id = "code_job")위 코드를 통해 잘 합쳐진 것을 확인할 수 있다.

사실 여기 비하인드 스토리가 있다..
나는 left_join() 함수의 인자로 by를 써서 합치는 거라고 생각했었는데 책에서는 id를 사용해서 합쳤다.
궁금증이 들어서 by로 합쳐보니 오류가 났다.
이상해서 책 앞을 찾아봤는데 아무리 봐도 오류가 나면 안 되는데..
내가 뭘 빼먹은지도 모르겠고 어디서부터 이해가 부족한지도 모르겠고ㅠㅠ
두 시간 동안 구글링 하다 결국 실패..
그래서 결국 책에 쓰여있는 데이터 분석 커뮤니티에 질문을 하려고 가입신청 넣어놓은 상태다..
알고리즘이나 web을 공부할 때는 세상 든든한 형들이 있어서 참 좋은데
데이터 분석은 궁금증을 해결하기가 쉽지 않다..
어쨌든 데이터 분석 커뮤니티에 물어보고 정확한 답변을 받은 뒤 아래에 수정할 예정임!
일단은 책에 나온 대로 따라가 보자!
# 직업별 월급 구하기
job_income <- welfare %>%
filter(!is.na(job) & !is.na(income)) %>% # job, income 결측치 제거
group_by(job) %>% # 직업별로 묶음
summarise(mean_income = mean(income)) # 평균 월급 구하기이젠 뭐..
이제 다음 순서는 말하지 않아도 그래프 출력~
근데 잠깐!
job_income 변수는 142*2의 크기를 가지고 있다.
이걸 전부 그래프로 만들면..?
그렇기 때문에 상위 10개 직업만 추출해서 만들어보자.

WOWOW!
금속 재료 공학 기술자 및 시험원이 어떤 직업이길래 의사, 고위공무원, 경영 관리자 다 제치고 1등이죠..?
뭐 그게 중요한 건 아니니까 일단 그래프로 만들어보자.
ggplot(data = top10, aes(x = mean_income, y = reorder(job, mean_income)))+
geom_col()
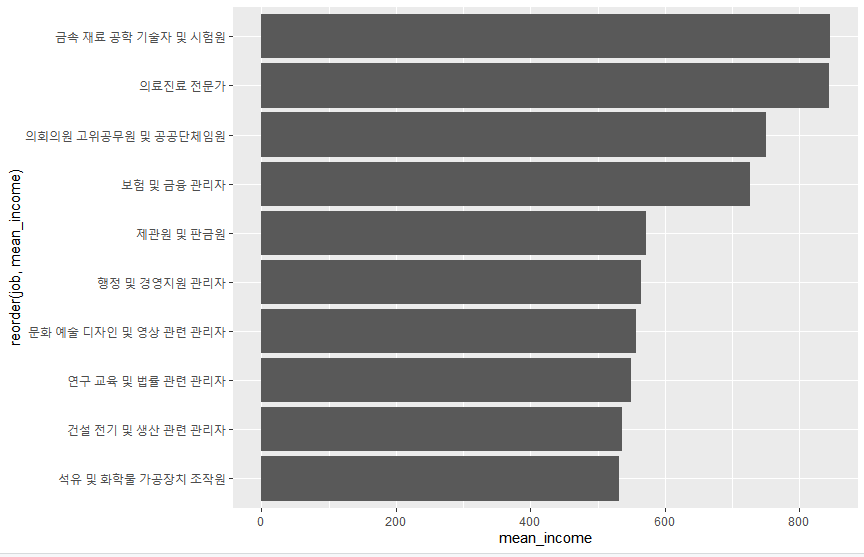
책에는 조금 다른 코드로 나와있지만 결국 똑같기 때문에..
이제 어느 정도 데이터 분석에 감은 잡히지만 그래도 어렵긴 하다.
오늘도 뭔가 공부했지만 불안한 느낌..
내일 다시 나머지 데이터 분석을 이어해 보자.
github.com/kimtaehyun98/Data_Analysis_Project1_-
kimtaehyun98/Data_Analysis_Project1_-
'한국복지패널' 데이터 분석을 통한 '한국인의 삶 파악' 프로젝트. Contribute to kimtaehyun98/Data_Analysis_Project1_- development by creating an account on GitHub.
github.com
'데이터 분석' 카테고리의 다른 글
| 9 일차 - 텍스트 마이닝 (0) | 2021.02.06 |
|---|---|
| 8 일차 - 데이터 분석 프로젝트 3 (0) | 2021.02.03 |
| 6 일차 - 데이터 분석 프로젝트 1 (0) | 2021.01.30 |
| 5 일차 - 그래프 만들기 (0) | 2021.01.28 |
| 4 일차 - 데이터 정제 (0) | 2021.01.27 |



