
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 데이터 분석
- 시뮬레이션
- 우선순위 큐
- 다익스트라
- r
- Bit
- 접미사 배열
- CI/CD
- jpa
- 백준 1753번
- Air Table
- 컴퓨터 구조
- 펜윅 트리
- 고속 푸리에 변환
- 수학
- JavaScript
- 이분탐색
- ICPC
- 생활코딩
- Cloud Pub/Sub
- 그리디
- 삼성SW역량테스트
- LCS
- BFS
- 종만북
- Cloud Run
- 다이나믹 프로그래밍
- 삼성 SW 역량테스트
- dp
- REACT
- Today
- Total
코딩스토리
6 일차 - 데이터 분석 프로젝트 1 본문
# 이 글을 "Do it! 쉽게 배우는 R 데이터 분석"의 내용을 바탕으로 작성한 글입니다.
드디어 본격적인 데이터 분석 프로젝트를 시작한다.
내가 분석할 데이터는 '한국 복지패널데이터'이다.
데이터의 분석과정을 간단하게 요약하면 다음과 같다.
1. 데이터 준비
2. 변수 검토 및 전처리
3. 변수 간 관계 분석
차근차근 하나씩 해보자.
먼저 데이터 준비는 완료했다.
해당 데이터는 SPSS 데이터이기 때문에 아래의 코드를 통해 데이터를 불러온다.
install.packages("foreign") # foreign 패키지 설치
library(foreign) # SPSS 파일 불러오기
library(dplyr) # 전처리
library(ggplot2) # 시각화
library(readxl) # 엑셀 파일 불러오기
# 데이터 불러오기
raw_welfare <- read.spss(file = "Koweps_hpc10_2015_beta1.sav",
to.data.frame = T)
# 'to.data.frame = T' 코드는 SPSS 파일을 데이터 프레임으로 변환!
# 복사본 만들기
welfare <- raw_welfare
다른 패키지들과 library 모두 앞에서 공부했으므로 넘어간다.
이렇게 데이터를 받아왔으면 알겠지만 데이터가 워낙 방대하고 변수들도 너무 많다.

무려 957개의 변수들.. 이걸 다 쓸 순 없다.
프로젝트에 사용할 변수 7개만 rename() 함수를 통해 바꿔준다.
# 분석에 사용하기 편하게 변수명 바꾸기
welfare <- rename(welfare,
sex = h10_g3, # 성별
birth = h10_g4, # 출생 년도
marriage = h10_g10, # 혼인 상태
religion = h10_g11, # 종교
income = p1002_8aq1, # 월급
code_job = h10_eco9, # 직업 코드
code_region = h10_reg7) # 지역 코드
이제 데이터 분석을 시작할 준비가 끝났다!
이제 이 데이터들을 바탕으로 분석을 해보자.
1. 성별에 따른 월급 차이
"성별에 따라 월급이 다를까?"
이 질문에 데이터를 바탕으로 답해보기 위해 데이터를 분석해보자.
먼저 '성별', '월급' 이 두 개의 데이터가 필요할 것 같다.
앞에서 공부했듯이 변수들을 검수해 '이상치'와 '결측치'를 제외해보자. (전처리 과정)
여기서 이상치를 판단하려면 먼저 '코드북'을 확인해야 한다.

코드북은 데이터에 대한 설명이 담겨있는 파일이다.
첫째 줄을 보면 알겠지만 모름/무응답이 9라고 적혀 있으므로 성별 변수의 이상치는 9에 해당할 것이다.
앞에서 배웠던 코드로 이상치가 얼마나 있는지 출력해보자.
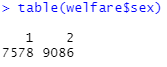
..? 1, 2를 제외하곤 다른 값은 존재하지 않는 것을 확인할 수 있다.
즉 이상치(9)가 존재하지 않는다.
이제 조금 더 알아보기 쉽게 변수의 값을 바꿔보자.
코드북에서 보다시피 1은 남자, 2는 여자이므로 알아보기 편하게 male, female로 바꿔보면

이렇게 어렵지 않게 성별 변수의 전처리 작업을 완료할 수 있다.
이제 나머지 월급 변수도 전처리 작업을 해보자.

해당 사진은 월급 변수에 대한 요약이다.
대충 최댓값과 최소, 평균값, 중앙값 등등이 보인다.
한번 그래프로 출력해보면

아이고.. 월급은 대부분 0~1000 사이에 몰려있고 그 이상은 거의 없어 보인다.
(당연하지.. 월급 데이터인데ㅠㅠ)
아쉬움은 뒤로 하고 다시 결측치, 이상치를 찾아서 전처리해보자.
코딩북을 보면 월급 변수는 9999가 미응답임을 알 수 있다.

와.. 결측치가 12044개나 된다.
자! 이제 변수 간 관계를 분석해보자!

살짝 어렵다ㅠ
아직은 익숙하지 않아서 그런 것 같다.
앞으로 많이 해봐야 될 듯..
이제 최종적으로 분석 결과를 그래프로 만들어보자.
# 그래프로 분석!
ggplot(data = sex_income, aes(x = sex, y = mean_income)) + geom_col()

이렇게 "성별과 월급과의 관계"를 데이터를 사용하여 분석해 보았다.
2. 나이와 월급의 관계
"몇 살 때 월급을 가장 많이 받을까?"
이 질문에 대한 답 또한 데이터를 통해 해 보자.
해당 분석에 필요한 변수는 '나이'변수와 '월급' 변수이다.
하지만 데이터에는 '나이'변수가 아닌 '생일' 변수가 존재하기 때문에 일단 '생일'변수를 전처리해보자.
생일 변수 역시 코드북을 통해 9999가 이상치임을 알 수 있다.
하지만 summarise()를 통해 요약한 내용을 보면 최댓값이 2014, 즉 이상치가 존재하지 않는다.
또한 is.na()를 통해 결측치도 존재하지 않음을 확인할 수 있다.

이제 생일 변수를 전처리했으므로 이 생일 변수를 통해 파생 변수인 '나이'변수를 만들어 보자.
# 'birth'를 통해 'age' 파생 변수 만들기
welfare$age <- 2015 - welfare$birth + 1 # 2015년에 조사 진행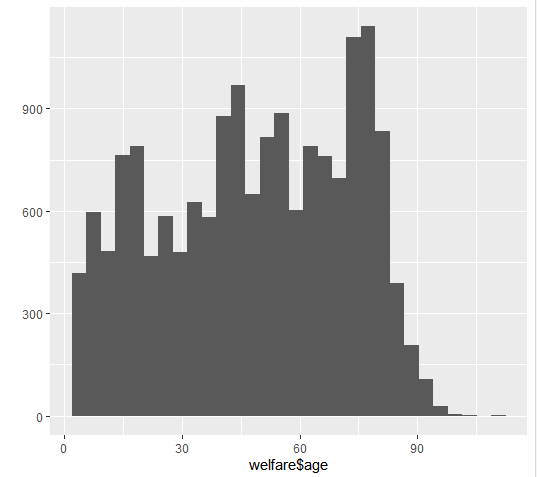
이제 '월급' 변수와 '나이'변수의 관계를 분석해보자!

와우..
그래프를 통해 40~60대가 월급을 300만 원가량 받으며 가장 높은 것을 확인할 수 있다.
당연한 말이지만ㅎㅎ
이렇게 첫 데이터 분석을 마쳤다.
이제 더 분석해야 할 것들이 몇 개 남아 있지만 진도에 맞춰 내일의 나에게 넘겨본다.
생각보다 간단하면서 뿌듯하다!
위의 코드는 아래 github에 남겨놓았어요!
github.com/kimtaehyun98/Data_Analysis_Project1_-
kimtaehyun98/Data_Analysis_Project1_-
'한국복지패널' 데이터 분석을 통한 '한국인의 삶 파악' 프로젝트. Contribute to kimtaehyun98/Data_Analysis_Project1_- development by creating an account on GitHub.
github.com
'데이터 분석' 카테고리의 다른 글
| 8 일차 - 데이터 분석 프로젝트 3 (0) | 2021.02.03 |
|---|---|
| 7 일차 - 데이터 분석 프로젝트 2 (0) | 2021.02.01 |
| 5 일차 - 그래프 만들기 (0) | 2021.01.28 |
| 4 일차 - 데이터 정제 (0) | 2021.01.27 |
| 3 일차 - 데이터 가공 (0) | 2021.01.26 |



