
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 백준 1753번
- 데이터 분석
- 우선순위 큐
- 생활코딩
- JavaScript
- r
- BFS
- Cloud Pub/Sub
- jpa
- 다이나믹 프로그래밍
- 다익스트라
- 펜윅 트리
- Air Table
- dp
- LCS
- CI/CD
- 삼성SW역량테스트
- 시뮬레이션
- 종만북
- Bit
- Cloud Run
- 그리디
- 컴퓨터 구조
- REACT
- 삼성 SW 역량테스트
- ICPC
- 수학
- 고속 푸리에 변환
- 이분탐색
- 접미사 배열
- Today
- Total
코딩스토리
DB Indexing - Read Row Count가 많다면? 본문
현재 진행하고 있는 프로젝트에서 PlanetScale이란 DB를 사용하고 있다.
해당 DB는 서버리스 기반으로 Read Row Count로 비용을 산출한다.
즉, 몇 개의 Row에 접근했는지에 따라 비용을 내야 한다.
하지만 무료 비용이 월 10억 번 접근이기 때문에 전혀 걱정하지 않고 있었다.
하지만 어느 날 서비스 분석을 하던 중, 7억 번의 접근을 했음을 확인했다.
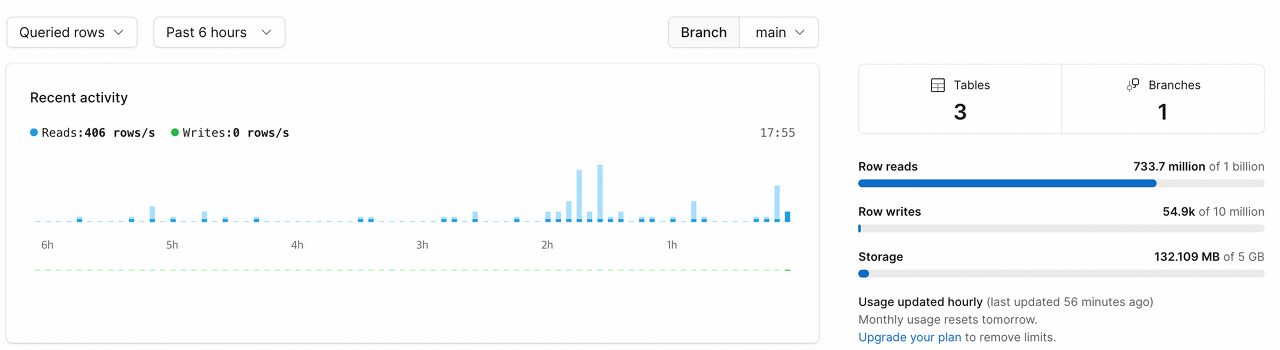
해당 DB는 "가사 제공 기능"과 관련하여 사용 중이다.
즉, 가사를 저장하고 있는 테이블이 주로 사용되고 있는데, 절대 저렇게 나올 수가 없다고 생각했다.
그래서 Insight를 확인해보니 아래와 같았다.

하루 동안 쿼리가 날아온 개수는 분명 717개인데, Rows read는 3900만 번이다.
즉, 한 번의 쿼리당 약 5만 번의 row를 읽었다는 것이다.
정확했다..
해당 테이블이 약 5만 개의 row를 가지고 있었고, where 절에 들어가는 id에 index를 걸어놓지 않았기 때문에 Full Scan을 할 수밖에 없었다.
좀 더 쉽게 설명하자면, id 값이 일치하는 row를 찾기 위해 무조건 테이블 내의 모든 row를 읽었다는 것이다.
분명 DB Indexing에 대해 공부했었고, 알고 있었지만 지금까지 꽤나 많은? 프로젝트를 하면서 적용해본 적이 없었다.
왜냐하면 쿼리를 짤 때 원하는 검색 결과가 나오면 테스트 통과였고, 실제 사용자가 없었기 때문에 이런 고민을 할 필요가 없었다.
하지만 이젠 서비스를 운영하는 입장이 되어보니 자칫하면 과금 폭탄도 받을 수 있었던 아찔한 상황이 되었다.
실제로 멘토님들께 이 상황을 알려드렸더니 DB Indexing을 안 걸은 게 더 놀랍다며.. 😭
실무에서는 무조건 where 절에 들어가는 모든 것에 index를 걸어준다고 한다.
이렇게 Indexing을 해주고 난 뒤 성능 비교는 아래와 같다.
[Before]

[After]

Query 평균 응답 시간이 48ms -> 2ms로 줄었다.
또 Row Read도 한 번의 쿼리 당 54000번 -> 1번으로 줄었다
이게 이렇게 구하는 게 맞는진 모르겠지만
평균 97% 이상의 성능 향상을 보이고 있다. 😆
실제로 ms 차이가 얼마나 크겠어라고 생각할 수 있는데 해당 API를 사용하는 기능을 사용해 보니 생각보다 차이가 느껴졌다.
어쨌든 실 서비스를 운영하면서 이러한 경험을 쌓아 가는 게 정말 좋은 경험인 것 같다.
'프로젝트' 카테고리의 다른 글
| Spring(Gradle) + DynamoDB CRUD 예제 (0) | 2022.10.10 |
|---|---|
| Air Table API 사용하여 자동화 파이프라인 구축 (0) | 2022.07.07 |
| Air Table과 Zapier 연동하여 Slack에 알림 메세지 전송하기 (4) | 2022.07.03 |
| AWS Lambda와 API Gateway 사용하여 메일링 코드 개발 (0) | 2022.07.03 |
| Sovled.ac 및 Github 잔디 프로젝트 (1) | 2022.05.28 |



